딕셔너리
는 리스트와 비슷하지만 좀 더 일반적입니다. 리스트에서, 지수는 정수만 가능합니다; 딕셔너리에서는 (거의) 모든 형이 가능합니다.
딕셔너리를 지수 (키(key)라고 불립니다) 와 값 간의 사상으로 볼 수 있습니다. 각 키는 값과 대응합니다. 키와 값의 결합을 키-값 쌍(key-value pair) 이나 때로 항목(item)이라고 부릅니다.
예를 들기 위해, 영어를 스페인어로 대응시키는 딕셔너리를 만들 것입니다. 키와 값은 모두 문자열입니다.
함수 dict는 항목이 없는 새 딕셔너리를 만듭니다. dict는 내장함수의 이름이기 때문에, 변수 명으로 쓰지 않도록 해야 합니다.
>>> eng2sp = dict()
>>> print eng2sp
{}
중괄호, {},는 빈 딕셔너리를 나타냅니다. 딕셔너리에 항목을 더하려면, 대괄호를 사용하면 됩니다:
>>> eng2sp['one'] = 'uno'
이 줄은 키 ’one’을 값 'uno' 에 대응시키는 항목을 만듭니다. 딕셔너리를 다시 인쇄해보면, 키와 값 사이에 콜론이 들어간 키-값 쌍을 볼 수 있습니다:
>>> print eng2sp
{'one': 'uno'}
이 출력 형식은 입력 형식이기도 합니다. 예를 들어, 세 개의 항목을 갖는 딕셔너리를 만들 수 있습니다:
>>> eng2sp = {'one': 'uno', 'two': 'dos', 'three': 'tres'}
그러나 eng2sp 를 인쇄해보면 놀랄 수도 있습니다:
>>> print eng2sp
{'one': 'uno', 'three': 'tres', 'two': 'dos'}
키-값 쌍의 순서가 다릅니다. 사실, 같은 예를 여러분의 컴퓨터에 입력해보면, 아마 다른 결과를 얻을 겁니다. 일반적으로, 딕셔너리에 들어있는 항목의 순서는 예측할 수 없습니다.
그러나 딕셔너리의 항목은 정수 지수를 사용하는 것이 아니므로 문제가 되지 않습니다. 대신에, 대응하는 값을 참조하기 위해 키를 사용합니다:
>>> print eng2sp['two']
'dos'
키 ’two’가 항상 값 'dos'에 대응하기 때문에 항목의 순서는 중요하지 않습니다.
만약 키가 딕셔너리에 없으면, 예외가 발생합니다:
>>> print eng2sp['four']
KeyError: 'four'
len 함수는 딕셔너리에 사용할 수 있습니다; 키-값 쌍의 개수를 돌려줍니다:
>>> len(eng2sp)
3
in 연산자도 딕셔너리에 사용할 수 있습니다; 딕셔너리의 키에 등장하는지를 알려줍니다 (값에 등장하는 것으로는 충분치 않습니다).
>>> 'one' in eng2sp
True
>>> 'uno' in eng2sp
False
뭔가가 딕셔너리의 값에 등장하는지 보려면, 메쏘드 values 를 사용해서 값들의 리스트를 얻은 후에, in 연산자를 쓸 수 있습니다:
>>> vals = eng2sp.values()
>>> 'uno' in vals
True
in 연산자는 리스트와 딕셔너리에 대해 다른 알고리즘을 사용합니다. 리스트의 경우, [find] 절에서 본 것과 같은 검색 알고리즘을 사용합니다. 리스트가 길어짐에 따라, 검색 시간도 정비례해서 길어집니다. 딕셔너리의 경우, 파이썬은 해시테이블(hashtable)이라고 불리는 알고리즘을 사용하는데, 주목할만한 성질을 갖고 있습니다: 딕셔너리에 얼마나 많은 항목이 들어있든 상관없이 in 연산자에는 일정한 시간이 걸립니다. 어떻게 이런 것이 가능한지 설명하지는 않겠지만, http://en.wikipedia.org/wiki/Hash_table 에서 자세한 내용을 읽을 수 있습니다.
[연습 11.1.] [wordlist2]
words.txt 에서 단어를 읽어 들인 후 딕셔너리의 키로 저장하는 함수를 작성하세요. 값으로 무엇을 사용하는지는 중요하지 않습니다. 그런다음 문자열이 딕셔너리에 있는지 검사하는 빠른 방법으로 in 연산자를 사용할 수 있습니다.
연습 [wordlist1]을 했다면, 이 구현의 속도를 리스트 in 연산자 및 이분 검색과 비교해볼 수 있습니다.
집합적 누산기로서의 딕셔너리
[histogram]
문자열이 주어지고 각 글자가 몇 번씩 나오는지 세고 싶다고 가정합시다. 여러 가지 방법이 있습니다:
- 알파벳의 글자당 하나씩 26개의 변수를 만들 수 있습니다. 그런 다음 문자열을 탐색하면서, 아마도 연쇄적인 조건 문을 사용해서, 각 글자마다 해당하는 누산기를 증가시킵니다.
- 26개의 요소를 갖는 리스트들 만들 수 있습니다. 그런 다음 각 문자를 (내장 함수 ord를 사용해서) 숫자로 바꾼 후, 리스트의 지수로 사용해서 적절한 누산기를 증가시킵니다.
- 문자들이 키이고, 누산기가 대응하는 값인 딕셔너리를 만들 수 있습니다. 문자를 처음 만날 때마다, 항목을 딕셔너리에 추가합니다. 그 후에는 이미 존재하는 항목의 값을 증가시킵니다.
이 방법들은 모두 같은 계산을 수행하지만, 각기 다른 방법으로 구현하고 있습니다.
구현(implementation)은 계산을 수행하는 방법입니다; 어떤 구현은 다른 구현보다 좋습니다. 예를 들어, 딕셔너리 구현의 장점 중 하나는 문자열에 어떤 글자가 나타날지 미리 알 필요가 없이, 나타나는 문자에 대한 자리만 만들어도 된다는 것입니다.
코드는 이런 식으로 구성됩니다:
def histogram(s):
d = dict()
for c in s:
if c not in d:
d[c] = 1
else:
d[c] += 1
return d
함수의 이름은 히스토그램(histogram) 인데, 한 세트의 누산기 (또는 빈도)를 뜻하는 통계 용어입니다.
함수의 첫 번째 줄은 빈 딕셔너리를 만듭니다. for 순환은 문자열을 탐색합니다. 매 순환마다, 문자 c가 딕셔너리에 없으면, 키가 c이고 (이 글자를 한 번 봤기 때문에) 초기 값이 1인 새 항목을 만듭니다. 만약 c가 이미 딕셔너리에 있으면 d[c] 를 증가시킵니다.
이런 식으로 동작합니다:
>>> h = histogram('brontosaurus')
>>> print h
{'a': 1, 'b': 1, 'o': 2, 'n': 1, 's': 2, 'r': 2, 'u': 2, 't': 1}
히스토그램이 보여주는 것은 글자 ’a’ 와 'b'는 한 번씩 등장하고, 'o' 는 두 번 등장하고, 등등입니다.
[연습 11.2.]
딕셔너리에는 키와 기본 값을 받는 get이라는 메쏘드가 있습니다. 키가 딕셔너리에 있으면 get은 대응하는 값을 돌려줍니다; 그렇지 않으면 기본 값을 돌려줍니다. 예를 들어:
>>> h = histogram('a')
>>> print h
{'a': 1}
>>> h.get('a', 0)
1
>>> h.get('b', 0)
0
get을 사용해서 histogram을 좀 더 간결하게 작성하세요. if 문을 제거할 수 있어야 합니다.
순환과 딕셔너리
딕셔너리를 for 문장에 사용하면, 딕셔너리의 키를 탐색합니다. 예를 들어, print_hist는 각 키와 대응하는 값을 인쇄합니다:
def print_hist(h):
for c in h:
print c, h[c]
출력은 이런 식입니다:
>>> h = histogram('parrot')
>>> print_hist(h)
a 1
p 1
r 2
t 1
o 1
다시 한번, 키에는 특별한 순서가 없습니다.
[연습 11.3.]
딕셔너리에는 keys 라는 메쏘드가 있는데 딕셔너리의 키를, 특별한 순서 없이, 리스트로 돌려줍니다.
print_hist 를 키와 그 값을 알파벳순으로 인쇄하도록 수정하세요.
역방향 조회
[raise]
주어진 딕셔너리 d와 키 k에 대해, 대응하는 값 v = d[k]를 찾는 것은 쉽습니다. 이 연산을 조회(lookup)라고 합니다.
하지만 v를 갖고 있고 k를 찾으려고 한다면 어떨까요? 두 가지 문제가 있습니다: 첫째로, 값 v로 대응하는 키가 여러 개 있을 수 있습니다. 응용에 따라, 하나를 선택하거나 그들 전부를 포함하는 리스트를 만들 수 있습니다. 둘째로, 역방향 조회(reverse lookup)를 하는 간단한 문법은 없습니다; 검색해야만 합니다.
여기에 값을 받아서 그 값에 대응하는 첫 번째 키를 돌려주는 함수가 있습니다:
def reverse_lookup(d, v):
for k in d:
if d[k] == v:
return k
raise ValueError
이 함수는 검색 패턴의 또 하나의 예입니다만, 전에는 보지 못했던 기능 raise를 사용합니다. raise 문은 예외를 일으킵니다; 이 경우에는 ValueError를 유발하는데, 일반적으로 매개변수의 값에 뭔가 잘못된 점이 있다는 것을 가리키는데 사용됩니다.
순환의 끝에 도달하면, v가 딕셔너리의 값에 존재하지 않는다는 뜻이고, 예외를 일으킵니다.
여기에 성공적인 역방향 조회의 예가 있습니다:
>>> h = histogram('parrot')
>>> k = reverse_lookup(h, 2)
>>> print k
r
그리고 성공적이지 못한 것도 있습니다:
>>> k = reverse_lookup(h, 3)
Traceback (most recent call last):
File "<stdin>", line 1, in ?
File "<stdin>", line 5, in reverse_lookup
ValueError
여러분이 예외를 일으킬 때의 결과는 파이썬이 일으킬 때와 같습니다: 트레이스백과 오류 메시지를 인쇄합니다.
raise 문은 자세한 오류 메시지를 선택적 인자로 받아들입니다. 예를 들어:
>>> raise ValueError, 'value does not appear in the dictionary'
Traceback (most recent call last):
File "<stdin>", line 1, in ?
ValueError: value does not appear in the dictionary
역방향 조회는 순방향 조회보다 많이 느립니다; 자주 수행해야 하거나 딕셔너리가 커지면 프로그램의 성능이 나빠질 것입니다.
[연습 11.4.]
reverse_lookup 를 수정해서, v에 대응하는 모든 키의 리스트나, 키가 없는 경우 빈 리스트를 돌려주도록 하세요.
딕셔너리와 리스트
[invert]
리스트는 딕셔너리의 값으로 쓰일 수 있습니다. 예를 들어, 글자를 빈도로 대응시키는 딕셔너리가 주어졌을 때, 뒤집고 싶을 수 있습니다; 즉, 빈도를 글자들로 대응시키는 딕셔너리를 만드는 겁니다. 같은 빈도를 보이는 글자가 여러 개 있을 수 있기 때문에, 뒤집힌 딕셔너리의 각 값들은 글자들의 리스트가 되어야 합니다.
여기 딕셔너리를 뒤집는 함수가 있습니다:
def invert_dict(d):
inverse = dict()
for key in d:
val = d[key]
if val not in inverse:
inverse[val] = [key]
else:
inverse[val].append(key)
return inverse
매 순환마다, key 는 d 로 부터 키를 취하고, val 은 대응하는 값이 됩니다. 만약 val이 inverseㅇ 없다면, 전에 보지 못한 값이라는 뜻이 되고, 새 항목을 만들어서 싱글톤(singleton)(하나의 요소를 갖는 리스트) 으로 초기화합니다. 그렇지 않으면 전에 본 값이고, 대응하는 키를 리스트에 덧붙입니다.
여기 예가 있습니다:
>>> hist = histogram('parrot')
>>> print hist
{'a': 1, 'p': 1, 'r': 2, 't': 1, 'o': 1}
>>> inverse = invert_dict(hist)
>>> print inverse
{1: ['a', 'p', 't', 'o'], 2: ['r']}
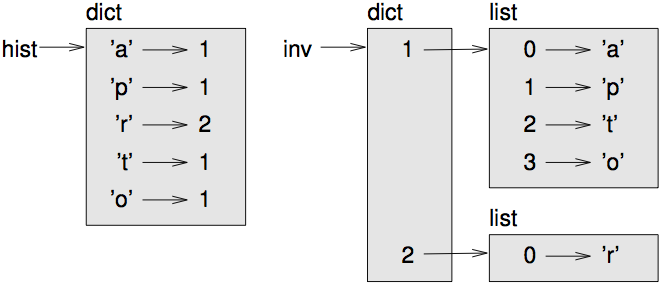
[fig.dict1]
그림 [fig.dict1]은 hist와 inverse를 보여주는 상태도 입니다. 딕셔너리는 위에 dict 형이 붙어있고 안에 키-값 쌍이 들어있는 상자로 표시됩니다. 값이 정수, 실수, 문자열이면 보통 상자 안에 그리지만, 다이어그램을 간단하게 유지하기 위해 리스트는 밖에 그립니다.
이 예가 보여주듯이, 이스트는 딕셔너리에서 값으로 쓰일 수 있습니다만, 키가 될 수는 없습니다. 시도하려고 하면 이렇게 됩니다:
>>> t = [1, 2, 3]
>>> d = dict()
>>> d[t] = 'oops'
Traceback (most recent call last):
File "<stdin>", line 1, in ?
TypeError: list objects are unhashable
앞에서 딕셔너리는 해시테이블을 사용해서 구현된다고 언급했는데, 이는 키가 해싱 가능(hashable)해야 한다는 뜻이 됩니다.
hash는 (어떤 종류이건) 값을 받아서 정수를 돌려주는 함수입니다. 딕셔너리는 이 정수, 해시 값이라고 불립니다,를 키-값 쌍을 저장하고 조회하는데 사용합니다.
이 시스템은 키가 수정 불가능하다면 잘 동작합니다. 그러나 키가, 리스트처럼, 수정 가능하면 나쁜 일이 일어납니다. 예를 들어, 키-값 쌍을 만들 때, 파이썬은 키를 해시하고 그 값에 대응하는 장소에 저장합니다. 만약 키를 수정한 후 다시 해시하면, 다른 장소로 가게 됩니다. 그 경우에 같은 키를 갖는 두 개의 항목을 갖게 되거나 키를 찾을 수 없게 됩니다. 두 경우 모두, 딕셔너리는 올바로 동작하지 않게 됩니다.
이 것이 키가 해싱 가능해야 하는 이유이고, 리스트와 같은 수정 가능한 형은 해싱 가능하지 않습니다. 이 한계를 피하는 가장 간단한 방법은 튜플(tuple)을 사용하는 것인데, 다른 장에서 보게 됩니다.
딕셔너리는 수정가능하기 때문에, 키로 사용될 수 없지만 값으로는 사용할 수 있습니다.
[연습 11.5.] 딕셔너리 메쏘드 setdefault의 설명서를 읽고 invert_dict 의 더 간략한 버전을 작성하세요. 답: http://thinkpython.com/code/invert_dict.py.
메모
[one.more.example] 절의 fibonacci 함수를 갖고 놀아봤다면, 더 큰 인자를 제공할 수록, 함수를 실행하는데 더 긴 시간이 걸린다는 것을 알아챘을 겁니다. 더 나아가, 실행 시간은 아주 빠르게 증가합니다.
어째서인지 이해하기 위해, 그림 [fig.fibonacci]를 보세요, n=4 일 때 fibonacci의 콜 그래프(call graph)를 보여줍니다:
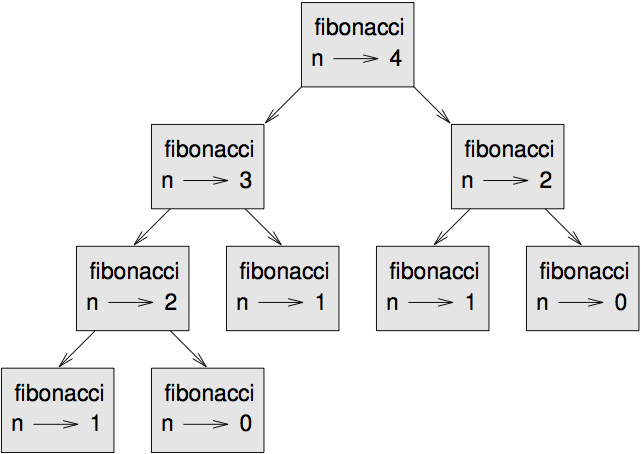
[fig.fibonacci]
콜 그래프는 한 세트의 함수 프레임을 보여주는데, 각 프레임을 호출하는 함수들의 프레임과 줄로 연결하고 있습니다. 그래프의 꼭대기에서, n=4 일 때의 fibonacci는 n=3 과 n=2 일 때의 fibonacci를 호출합니다. 차례대로, n=3일 때의 fibonacci는 n=2 와 n=1 일 때의 fibonacci를 호출합니다. 이런 식으로 계속 이어집니다.
fibonacci(0) 과 fibonacci(1)가 몇 번 호출되었는지 세어 보세요. 이 것은 비효율적인 해법이고, 인자가 커질 수록 더 나빠집니다.
한가지 해법은 딕셔너리에 저장함으로써 이미 계산된 값들을 관리하는 것입니다. 앞서 계산된 값들을 나중에 사용하기 위해 저장하는 것을 메모(memo)라고 부릅니다. 여기 메모를 사용한 fibonacci의 구현이 있습니다:
known = {0:0, 1:1}
def fibonacci(n):
if n in known:
return known[n]
res = fibonacci(n-1) + fibonacci(n-2)
known[n] = res
return res
known은 이미 알고 있는 피보나치 수를 유지하기 위한 딕셔너리입니다. 두 개의 항목으로 시작합니다: 0 은 0으로 대응하고, 1은 1로 대응합니다.
fibonacci가 호출될 때마다, known을 검사합니다. 그곳에 결과가 이미 있다면, 즉시 반환할 수 있습니다. 그렇지 않다면, 새 값을 계산해야만 하고, 딕셔너리에 추가한 후 돌려줍니다.
[연습 11.6.]
매개변수를 바꿔가며 이 버전의 fibonacci 와 원본을 실행하고 실행 시간을 비교하세요.
[연습 11.7.]
연습 [ackermann]의 애커만 함수를 메모화하고 메모화가 더 큰 인자로 함수를 호출할 수 있도록 만드는지 보세요. 힌트: 아닙니다. 답: http://thinkpython.com/code/ackermann_memo.py.
전역 변수
앞의 예에서, known은 함수의 바깥에 만들어져서, __main__ 이라 불리는 특별한 프레임에 속합니다. __main__ 에 있는 변수들을 때로 전역(global)이라고 하는데, 그들은 아무 함수에서건 참조할 수 있기 때문입니다. 함수가 종료할 때 사라지는 지역변수와는 달리, 전역 변수는 한 함수 호출에서 다음으로 넘어갈 때 계속 남아있습니다.
종종 전역변수를 플래그(flag)로 사용하는데, 조건이 참인지를 가리키는 (“flag”) 논리 변수를 뜻합니다. 예를 들어, 어떤 프로그램은 출력의 상세한 정도를 제어하기 위해 verbose라는 이름의 플래그를 사용합니다:
verbose = True
def example1():
if verbose:
print 'Running example1'
전역 변수를 다시 대입하려고 하면, 놀랄 수 있습니다. 다음 예는 함수가 호출되었는지를 추적한다고 여겨집니다:
been_called = False
def example2():
been_called = True # WRONG
하지만 실행해 보면 been_called 의 값이 바뀌지 않는 것을 볼 수 있습니다. 문제는 example2가 been_called라는 이름의 새 지역 변수를 만드는데 있습니다. 지역 변수는 함수가 종료할 때 사라지고, 전역 변수에는 어떤 영향도 주지 않습니다.
함수 내에서 전역 변수를 다시 대입하려면 사용하기 전에 전역 변수를 선언(declare)해야 합니다:
been_called = False
def example2():
global been_called
been_called = True
global 문은 인터프리터에게 이렇게 알립니다, “이 함수에서, 내가 been_called 를 언급하면, 전역 변수를 뜻하는 것입니다; 지역 변수를 만들지 마세요.”
여기에 전역 변수를 갱신하려고 시도하는 예가 있습니다:
count = 0
def example3():
count = count + 1 # WRONG
실행하면 이렇게 됩니다:
UnboundLocalError: local variable 'count' referenced before assignment
파이썬은 count 가 지역 변수라고 가정하는데, 쓰기 전에 읽고 있다는 뜻이 됩니다. 해법은, 다시, count를 전역으로 선언하는 것입니다.
def example3():
global count
count += 1
만약 전역 변수가 수정 가능하면, 선언하지 않고 수정할 수 있습니다:
known = {0:0, 1:1}
def example4():
known[2] = 1
그래서 전역 리스트와 딕셔너리의 요소들을 추가하고, 삭제하고, 바꿀 수 있습니다만, 변수를 다시 대입하기 원한다면 선언해야만 합니다:
def example5():
global known
known = dict()
긴 정수
fibonacci(50)을 계산하면, 이렇게 됩니다:
>>> fibonacci(50)
12586269025L
끝에 붙은 L은 결과가 긴 정수, 또는 long 형, 임을 가리킵니다. 파이썬 3에서, long은 사라졌습니다; 아주 큰 것까지 포함해서, 모든 정수는 int 형입니다.
int 형의 값은 제한된 범위를 갖습니다; 긴 정수는 제한 없이 커질 수 있습니다만, 커질 수록 더 많은 공간과 시간을 소모합니다.
수학 연산자는 긴 정수에 사용할 수 있고, math 모듈에 있는 함수들 역시 그렇기 때문에, 일반적으로 int 와 사용할 수 있는 코드들은 long과도 사용할 수 있습니다.
계산의 결과가 정수로 표현하기에 너무 클 때마다, 파이썬은 결과를 긴 정수로 바꿉니다:
>>> 1000 * 1000
1000000
>>> 100000 * 100000
10000000000L
첫 번째 경우에 결과는 int 형입니다; 두 번째 경우에는 long입니다.
[연습 11.8.]
큰 정수의 지수화(exponentiation)는 공개키 암호화 알고리즘들의 공통적인 기초를 이룹니다. RSA 알고리즘에 관한 위키피디아 페이지(http://en.wikipedia.org/wiki/RSA)를 읽고 메시지를 암호화하고 복호화하는 함수를 작성하세요.
디버깅
더 큰 자료로 작업하게 됨에 따라 인쇄하고 손으로 검사하는 방식으로 디버깅하기 버겁게 됩니다. 여기 큰 자료를 디버깅하는데 대한 몇 가지 제안이 있습니다:
- 입력의 규모를 줄이세요:
가능하다면, 자료의 크기를 줄이세요. 예를 들어 프로그램이 텍스트 파일을 읽는다면, 처음 10줄 혹은 여러분이 찾을 수 있는 가장 작은 예로 시작하세요. 파일 자체를 편집하거나, (이게 더 좋은데) 첫 n 줄만을 읽도록 프로그램을 수정하세요.
오류가 있다면, n을 오류가 발생하는 최소 값으로 줄일 수 있고, 오류를 발견하고 수정함에 따라 점진적으로 증가시킵니다.
- 요약과 형을 검사하세요:
자료 전체를 인쇄하고 검사하는 대신, 자료의 요약을 인쇄하는 것을 고려하세요: 예를 들어, 딕셔너리에 있는 항목의 개수나 숫자 목록의 합계.
실행시간 오류의 일반적인 원인 중 하나는 올바를 형을 갖고 있지 않은 값입니다. 이런 종류의 오류를 디버깅하는 데는, 종종 값의 형을 인쇄하는 것으로 충분합니다.
- 자기 검사를 작성하세요:
때로 스스로 오류를 검사하는 코드를 작성할 수 있습니다. 예를 들어, 숫자 목록의 평균을 계산한다면, 결과가 목록의 가장 큰 값보다 크지 않다거나 목록의 가장 작은 값보다 작지 않음을 검사할 수 있습니다. 이런 것을 “새너티(sanity) 검사” 라고 하는데 말도 안 되는(“insane”) 결과를 감지하기 때문입니다.
또 다른 종류의 검사는 두 가지 다른 계산의 결과를 비교해서 일관성이 있는지 봅니다. 이 것을 “일관성 검사”라고 합니다.
- 출력을 보기 좋게 인쇄하세요:
- 디버깅 출력을 정돈하는 것은 오류를 발견하기 쉽게 만들 수 있습니다. 우리는 [factdebug] 절에서 예를 봤습니다. pprint 모듈은 사람이 읽는데 더 적합한 형식으로 내장 형들을 인쇄해주는 pprint 함수를 제공합니다.
다시 한번, 비계(scaffold)를 만드는데 들인 시간은 디버깅에 쓸 시간을 줄여줄 수 있습니다.
용어
- 딕셔너리 dictionary:
- 키 집합으로부터 대응하는 값들로의 사상.
- 키-값 쌍 key-value pair:
- 키로부터 값으로의 대응을 표현한 것.
- 항목 item:
- 키-값 쌍의 다른 이름.
- 키 key:
- 키-값 쌍의 첫 번째 부분으로써 딕셔너리에 등장하는 객체.
- 값 value:
- 키-값 쌍의 두 번째 부분으로써 딕셔너리에 등장하는 객체. 이 것은 앞서 사용한 단어 “값”보다 더 구체적인 용법입니다.
- 구현 implementation:
- 계산을 수행하는 방법.
- 해시테이블 hashtable:
- 파이썬 딕셔너리를 구현하는데 사용된 알고리즘.
- 해시 함수 hash function:
- 키의 장소를 계산하기 위해 해시테이블에서 사용되는 함수.
- 해싱가능 hashable:
- 해시 함수를 갖는 형. 정수, 실수, 문자열과 같이 수정 불가능한 형은 해싱 가능하다; 리스트와 딕셔너리처럼 수정 가능한 형은 그렇지 않다.
- 조회 lookup:
- 키를 받아서 대응하는 값을 찾는 딕셔너리 연산.
- 역방향 조회 reverse lookup:
- 값을 받아서 하나나 그 이상의 대응하는 키를 찾는 딕셔너리 연산.
- 싱글톤 singleton:
- 하나의 요소만을 갖는 리스트 (또는 다른 시퀀스).
- 콜 그래프 call graph:
- 프로그램이 실행되는 도중 만들어지는 모든 프레임을 보여주는 다이어그램으로, 호출자에서 피호출자로 가는 화살표를 포함한다.
- 히스토그램 histogram:
- 한 세트의 누산기.
- 메모 memo:
- 불필요한 미래의 계산을 피하기 위해 저장된 계산 값.
- 전역 변수 global variable:
- 함수 바깥에서 정의된 변수. 전역 변수는 아무 함수에서나 참조할 수 있다.
- 플래그 flag:
- 조건이 참인지를 가리키기 위해 사용되는 논리 변수.
- 선언 declaration:
- global 과 같은 문장으로 인터프리터에게 변수에 관한 무엇인가를 전달한다.
연습
[연습 11.9.]
연습 [duplicate]를 했다면, 이미 리스트를 매개변수로 받아서 두 번 이상 등장하는 객체가 존재하면 True를 돌려주는 함수 has_duplicates를 갖고 있습니다.
딕셔너리를 사용해서 더 빠르고 간단한 버전의 has_duplicates를 작성하세요. 답: http://thinkpython.com/code/has_duplicates.py.
[연습 11.10.] [exrotatepairs]
한 단어를 회전시켜서 다른 하나를 만들 수 있을 때, 두 단어를 “회전 쌍(rotate pairs)” 이라고 합니다(연습 [exrotate]에 있는 rotate_word를 보세요).
단어목록을 읽어서 모든 회전 쌍을 찾는 프로그램을 작성하세요. 답: http://thinkpython.com/code/rotate_pairs.py.
[연습 11.11.]
여기 Car Talk(http://www.cartalk.com/content/puzzlers)에 나온 또 하나의 퍼즐이 있습니다:
이 것은 Dan O’Leary 라는 친구가 보낸 것입니다. 그는 평범한 단음절의 다섯 글자 단어가 다음과 같이 특이한 성질을 갖고 있는 것을 발견했습니다. 첫 글자를 지우면, 남은 글자들은 원래 단어와 동음이의어, 즉 발음이 정확히 같은 단어를 이룹니다. 첫 글자를 바꾸세요, 즉 원상태로 돌린 후에 두 번째 글자를 지우면 이 역시 동음이의어가 됩니다. 질문은 이렇습니다, 어떤 단어일까요?
이제 틀린 예를 제시하려고 합니다. 다섯 글자 단어 ‘wrack’을 봅시다. 첫 번째 글자를 지우면, 네 글자 단어 ’R-A-C-K’ 이 남습니다. 완벽한 동음이의어입니다. ‘w’를 다시 넣고, ‘r’을 대신 지우면 단어 ‘wack’이 남는데, 진짜 단어이기는 하지만 동음이의어는 아닙니다.
하지만 Dan 과 우리가 알고 있는 단어가 적어도 하나가 있는데, 처음 두 글자 중 어느 하나를 지워도, 남는 네 글자 단어는 원래 단어와 동음이의어를 이룹니다. 질문은 이렇습니다, 단어는 무엇일까요?
문자열이 단어 목록에 있는지 검사하는데 연습 [wordlist2]의 딕셔너리를 사용할 수 있습니다.
두 단어가 동음이의어인지 검사하려면, CMU 발음 사전(CMU Pronouncing Dictionary)을 사용할 수 있습니다. http://www.speech.cs.cmu.edu/cgi-bin/cmudict 나 http://thinkpython.com/code/c06d에서 다운로드 할 수 있는 발음 사전 외에도, http://thinkpython.com/code/pronounce.py 도 다운로드 할 수 있는데, 이 파일이 제공하는 함수 read_dictionary 는 발음 사전을 읽어서 각 단어를 기본 발음을 표현하는 문자열에 대응시키는 파이썬 딕셔너리를 돌려줍니다.
퍼즐의 답이 되는 모든 단어를 나열하는 프로그램을 작성하세요. 답: http://thinkpython.com/code/homophone.py.