튜플
[tuplechap]
튜플은 수정 불가능
튜플은 값의 시퀀스입니다. 값은 어떤 것이건 될 수 있고, 정수를 지수로 사용한다는 점에서 리스트와 매우 유사합니다. 중요한 차이는 튜플이 수정 불가능하다는 것입니다.
문법적으로, 튜플은 쉼표로 분리된 값들의 나열입니다:
>>> t = 'a', 'b', 'c', 'd', 'e'
꼭 필요하지는 않지만, 보통 괄호로 튜플을 감싸줍니다:
>>> t = ('a', 'b', 'c', 'd', 'e')
한 개의 값으로 튜플을 만들려면, 끝에 쉼표를 붙여줘야 합니다:
>>> t1 = 'a',
>>> type(t1)
<type 'tuple'>
괄호 안의 값은 튜플이 아닙니다:
>>> t2 = ('a')
>>> type(t2)
<type 'str'>
튜플을 만드는 다른 방법은 내장함수 tuple입니다. 인자가 없으면, 빈 튜플을 만듭니다:
>>> t = tuple()
>>> print t
()
인자가 시퀀스 (문자열, 리스트, 튜플)면, 결과는 시퀀스의 요소들로 구성된 튜플입니다:
>>> t = tuple('lupins')
>>> print t
('l', 'u', 'p', 'i', 'n', 's')
tuple은 내장 함수의 이름이기 때문에, 변수 명으로 사용하지 말아야 합니다.
대부분의 리스트 연산자는 튜플에서도 동작합니다. 대괄호 연산자는 요소를 지정합니다:
>>> t = ('a', 'b', 'c', 'd', 'e')
>>> print t[0]
'a'
슬라이스 연산자는 요소들의 일부를 선택합니다.
>>> print t[1:3]
('b', 'c')
그러나 튜플의 요소 하나를 수정하려고 하면, 오류가 발생합니다:
>>> t[0] = 'A'
TypeError: object doesn't support item assignment
튜플의 요소들을 수정할 수는 없습니다만, 하나의 튜플을 다른 튜플로 바꿀 수는 있습니다:
>>> t = ('A',) + t[1:]
>>> print t
('A', 'b', 'c', 'd', 'e')
튜플 대입
[tuple.assignment]
두 변수의 값을 교환하는 것이 유용합니다. 전통적인 방식의 대입을 쓸 때는, 임시 변수를 사용해야 합니다. 예를 들어, a 와 b를 교환하려면:
>>> temp = a
>>> a = b
>>> b = temp
이 해법은 성가십니다; 튜플 대입이 더 우아합니다:
>>> a, b = b, a
좌변은 변수들의 튜플입니다; 우변은 표현식들의 튜플입니다. 각 값들은 대응하는 변수들에 대입됩니다. 우변의 모든 표현식들은 모든 대입 이전에 환산됩니다.
왼쪽에 있는 변수들의 개수와 오른쪽에 있는 값들의 개수는 일치해야 합니다:
>>> a, b = 1, 2, 3
ValueError: too many values to unpack
더 일반적으로, 우변은 모든 종류의 시퀀스가 (문자열, 리스트, 튜플) 될 수 있습니다. 예를 들어, 이메일 주소를 사용자 이름과 도메인으로 나누려면, 이렇게 쓸 수 있습니다:
>>> addr = 'monty@python.org'
>>> uname, domain = addr.split('@')
split의 반환 값은 두 개의 요소가 있는 리스트입니다; 첫 번째 요소는 uname에 대입되고, 두 번째는 domain에 대입됩니다.
>>> print uname
monty
>>> print domain
python.org
튜플 반환 값
엄밀하게 말할 때, 함수는 오직 하나의 값만을 돌려줄 수 있습니다만, 만약 그 값이 튜플이라면, 효과는 여러 개의 값을 돌려주는 것과 마찬가지 입니다. 예를 들어, 만약 두 정수로 나눗셈을 해서, 몫과 나머지를 계산하고자 한다면, x/y 를 계산 한 후에 x%y 를 계산하는 것은 비효율적입니다. 두 값을 함께 계산하는 것이 더 좋습니다.
내장 함수 divmod는 두 개의 인자를 받아들여서, 두 값, 몫과 나머지, 의 튜플을 돌려줍니다. 결과를 튜플로 저장할 수 있습니다:
>>> t = divmod(7, 3)
>>> print t
(2, 1)
또는 각 요소들을 따로 저장하기 위해 튜플 대입을 사용할 수 있습니다:
>>> quot, rem = divmod(7, 3)
>>> print quot
2
>>> print rem
1
여기에 튜플을 돌려주는 함수의 예가 있습니다:
def min_max(t):
return min(t), max(t)
max 와 min은 시퀀스에서 가장 큰 요소와 가장 작은 요소를 찾는 내장함수입니다. min_max 는 둘 다 계산해서 두 값의 튜플을 돌려줍니다.
가변길이 인자 튜플
함수는 고정되지 않은 개수의 인자를 받아들일 수 있습니다. 로 시작하는 매개변수 이름은 인자들을 튜플로 수집(gather)합니다. 예를 들어, printall은 임의의 개수의 인자들을 받아들여서, 그들을 인쇄합니다:
def printall(*args):
print args
수집 매개변수는 여러분이 원하는 어떤 이름이건 될 수 있습니다만, args가 자주 쓰입니다. 함수는 이런 식으로 동작합니다:
>>> printall(1, 2.0, '3')
(1, 2.0, '3')
수집의 반대는 산개(scatter)입니다. 값의 시퀀스가 있고 함수에 여러 개의 인자로 전달하고 싶다면, 연산자를 사용할 수 있습니다. 예를 들어, divmod 는 정확히 두 개의 인자를 받아들입니다; 튜플은 사용할 수 없습니다:
>>> t = (7, 3)
>>> divmod(t)
TypeError: divmod expected 2 arguments, got 1
그러나 튜플을 산개한다면, 동작합니다:
>>> divmod(*t)
(2, 1)
[연습 12.1.]
여러 내장함수들은 가변길이 인자 튜플을 사용합니다. 예를 들어, max와 min은 몇 개의 인자든 받아들일 수 있습니다:
>>> max(1,2,3)
3
하지만 sum은 그렇지 않습니다.
>>> sum(1,2,3)
TypeError: sum expected at most 2 arguments, got 3
몇 개의 인자든 받아들여서 그들의 합을 돌려주는 함수 sumall을 작성하세요.
리스트와 튜플
zip은 두 개나 그 이상의 시퀀스를 받아들여서 튜플들의 리스트로 “집(zip)” 하는데, 각 튜플은 각 시퀀스들로부터 요소를 하나씩 받아 만들어집니다. 파이썬 3에서, zip은 튜플의 이터레이터(iterator)를 돌려줍니다만, 대부분의 목적에서 이터레이터는 리스트처럼 동작합니다.
이 예는 문자열과 리스트를 zip 합니다:
>>> s = 'abc'
>>> t = [0, 1, 2]
>>> zip(s, t)
[('a', 0), ('b', 1), ('c', 2)]
결과는 튜플의 리스트인데, 각 튜플은 문자열에서 온 문자와 리스트의 해당 요소로 구성됩니다.
만약 시퀀스들의 길이가 같지 않다면, 결과는 가장 짧은 것의 길이를 갖습니다.
>>> zip('Anne', 'Elk')
[('A', 'E'), ('n', 'l'), ('n', 'k')]
튜플의 리스트를 탐색하는 for 순환에서 튜플 대입을 사용할 수 있습니다:
t = [('a', 0), ('b', 1), ('c', 2)]
for letter, number in t:
print number, letter
매 순환 마다, 파이썬은 리스트의 다음 튜플을 선택하고 요소들을 letter 와 number에 대입합니다. 이 순환의 출력은 이렇습니다:
0 a
1 b
2 c
zip 과 for 와 튜플 대입을 결합하면, 두 (또는 그 이상의) 시퀀스를 동시에 탐색하는 유용한 관용구를 얻습니다. 예를 들어, has_match 는 두 시퀀스, t1 과 t2,를 받아들여서 t1[i] == t2[i] 이 성립하는 지수 i가 존재하면 True를 돌려줍니다:
def has_match(t1, t2):
for x, y in zip(t1, t2):
if x == y:
return True
return False
시퀀스의 요소와 그들의 지수를 탐색할 필요가 있으면, 내장 함수 enumerate를 사용할 수 있습니다:
for index, element in enumerate('abc'):
print index, element
이 순환의 출력은 이렇습니다:
0 a
1 b
2 c
앞의 결과와 같지요.
딕셔너리와 튜플
[dictuple]
딕셔너리에는 items 이라는 메쏘드가 있어서 튜플의 리스트를 돌려주는데, 각 튜플은 키-값 쌍입니다.
>>> d = {'a':0, 'b':1, 'c':2}
>>> t = d.items()
>>> print t
[('a', 0), ('c', 2), ('b', 1)]
딕셔너리라는 것에서 짐작하듯이, 항목들은 특별한 순서를 갖고 있지 않습니다. 파이썬 3에서, items는 이터레이터를 돌려주는데, 많은 목적에서 이터레이터는 리스트처럼 행동합니다.
다른 방향으로 가서, 튜플의 리스트를 새 딕셔너리를 초기화하는데 사용할 수 있습니다:
>>> t = [('a', 0), ('c', 2), ('b', 1)]
>>> d = dict(t)
>>> print d
{'a': 0, 'c': 2, 'b': 1}
dict 와 zip 을 결합하면 딕셔너리를 만드는 간결한 방법을 얻습니다:
>>> d = dict(zip('abc', range(3)))
>>> print d
{'a': 0, 'c': 2, 'b': 1}
딕셔너리 메쏘드 update 또한 튜플의 리스트를 받아들이는데, 기존의 딕셔너리에 그들, 키-값 쌍으로,을 추가합니다.
items 와 튜플 대입과 for를 결합하면, 딕셔너리의 키와 값들을 탐색하는 관용구를 얻습니다:
for key, val in d.items():
print val, key
이 순환의 출력은 이렇습니다:
0 a
2 c
1 b
또 만났네요.
튜플은 (주로 리스트를 사용할 수 없기 때문에) 딕셔너리의 키로 자주 사용됩니다. 예를 들어, 전화번호부는 성, 이름 쌍을 전화 번호로 대응시킵니다. last, first, number 를 정의했다고 가정할 때, 이렇게 쓸 수 있습니다:
directory[last,first] = number
대괄호 안의 표현식은 튜플입니다. 이 딕셔너리를 탐색하기 위해 튜플 대입을 사용할 수 있습니다.
for last, first in directory:
print first, last, directory[last,first]
이 순환은 directory 의 키를 탐색하는데, 키가 튜플입니다. 각 튜플을 last 와 first에 대입한 다음, 이름과 그에 대응하는 전화번호를 인쇄합니다.
상태도에 튜플을 표시하는 두 가지 방법이 있습니다. 더 상세한 버전은 리스트에서와 마찬가지로 지수와 요소들을 보여줍니다. 예를 들어, 튜플 ('Cleese', 'John') 는 그림 [fig.tuple1] 처럼 표시됩니다.
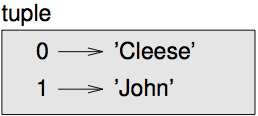
[fig.tuple1]
그러나 더 큰 다이어그램에서는 자세한 내용을 생략하고 싶을 겁니다. 예를 들어, 전화번호부의 다이어그램은 그림 [fig.dict2] 처럼 표시할 수 있습니다.
[fig.dict2]
여기에서 튜플은 도식적 약기로 파이썬 문법을 사용해서 표시됩니다.
다이어그램에 나오는 번호는 BBC 의 고객상담번호이니 전화 걸지 말아주세요.
튜플 비교하기
비교 연산자는 튜플과 다른 시퀀스들에 사용할 수 있습니다; 파이썬은 각 시퀀스의 첫 번째 요소를 비교하는 것으로 시작합니다. 만약 그들이 같다면, 다음 요소로 넘어가고, 다른 요소들을 발견할 때까지 이런 과정을 계속합니다. (설사 그들이 아주 크다고 할지라도) 뒤에 남은 요소들은 고려하지 않습니다.
>>> (0, 1, 2) < (0, 3, 4)
True
>>> (0, 1, 2000000) < (0, 3, 4)
True
sort 함수도 같은 식으로 동작합니다. 기본적으로 첫 번째 요소로 정렬하지만, 같은 경우에 두 번째 요소를 사용하고, 이런 식으로 계속됩니다.
이 기능은 DSU 라고 부르는 패턴을 만들어내는데, 다음의 줄임 말입니다.
- Decorate
- 시퀀스의 요소 앞에 하나나 그 이상의 키를 붙인 튜플의 목록을 만듦으로써 시퀀스를 장식(decorate)하고,
- Sort
- 튜플의 리스트를 정렬(sort) 한 후,
- Undecorate
- 시퀀스의 정렬된 요소들을 추출해 냄으로써 장식을 해제(undecorate)합니다.
[DSU]
예를 들어, 가장 긴 것에서 짧은 것 순으로 정렬하고 싶은 단어들의 리스트가 있다고 합시다:
def sort_by_length(words):
t = []
for word in words:
t.append((len(word), word))
t.sort(reverse=True)
res = []
for length, word in t:
res.append(word)
return res
첫 번째 순환은 튜플이 리스트를 만드는데, 각 튜플은 그 길이가 앞에 나오는 단어입니다.
sort는 첫 번째 요소 length 를 먼저 비교하고, 같을 경우에만 두 번째 요소를 고려합니다. 키워드 인자 reverse=True는 sort에게 내림차순임을 지시합니다.
두 번째 순환은 튜플의 리스트를 탐색하면서, 길이의 내림차순으로 정렬된 단어들의 리스트를 만듭니다.
[연습 12.2.]
이 예에서, 길이가 같을 때는 단어를 비교하기 때문에, 같은 길이의 단어들은 알파벳 역순으로 나오게 됩니다. 다른 응용에서 길이가 같을 때는 임의의 순서로 나오게 하고 싶을 수 있습니다. 이 예를 길이가 같은 단어들이 임의의 순서로 나타나게 수정하세요. 힌트: random 모듈의 random 함수를 보세요. 답: http://thinkpython.com/code/unstable_sort.py.
시퀀스의 시퀀스
튜플의 리스트에 집중했습니다만, 이 장의 거의 모든 예는 리스트의 리스트, 튜플의 튜플, 리스트의 튜플에 대해서도 동작합니다. 모든 가능한 조합을 나열하는 대신데, 시퀀스의 시퀀스에 대해서 말하는 게 더 간편합니다.
많은 경우에, 다른 종류의 시퀀스 (문자열, 리스트, 튜플)들은 바꿔 사용될 수 있습니다. 그렇다면 어떻게 그리고 왜 특정한 한가지 종류를 선택할까요?
자명한 것부터 시작해보면, 문자만을 요소로 가질 수 있는 문자열은 다른 시퀀스들보다 더 제한적입니다. 수정 불가능하기도 합니다. (새 문자열을 만드는 대신) 문자열에 있는 문자를 변경하는 능력이 필요하다면, 문자의 리스트를 사용하고 싶을 겁니다.
리스트는 튜플보다 자주 쓰이는데, 대부분 수정 가능하기 때문입니다. 그러나 튜플을 선호할 몇 가지 경우가 있습니다:
- return 문과 같은 몇몇 경우에 리스트 대신에 튜플을 만드는 것이 문법적으로 더 간단합니다. 다른 경우에는 아마도 리스트를 선호할겁니다.
- 시퀀스를 딕셔너리의 키로 사용하려면, 튜플이나 문자열 같이 수정 불가능한 형을 사용해야만 합니다.
- 시퀀스를 함수에 인자로 전달하고 있다면, 튜플을 사용하는 것이 애일리어싱으로 인한 예상치 못한 행동의 위험을 줄입니다.
튜플은 수정불가능하기 때문에, 기존의 리스트를 수정하는 sort 와 reverse 같은 메쏘드들을 제공하지 않습니다. 그러나 파이썬은 내장 함수 sorted 와 reversed를 제공하는데, 모든 종류의 시퀀스를 인자로 받아들여서 순서를 바꾼 새 리스트를 돌려줍니다.
디버깅
리스트, 딕셔너리, 튜플은 자료 구조라는 포괄적인 용어로 알려져 있습니다; 이 장에서 우리는 튜플의 리스트나 튜플을 키로 하고 리스트를 값으로 갖는 딕셔너리와 같은 복합 자료 구조를 보기 시작했습니다. 복합 자료 구조는 유용합니다만, 제가 형태(shape) 오류라고 부르는 것에 취약한데, 자료 구조가 잘못된 형, 크기, 조성(composition)을 가짐으로써 유발되는 오류를 뜻합니다. 예를 들어, 여러분이 정수 하나가 들어있는 리스트를 기대하고 있을 때 제가 그냥 (리스트에 들어있지 않은) 정수만 준다면, 뜻한 데로 동작하지 않을 것입니다.
이런 종류의 오류를 디버깅하기 쉽도록 하기 위해, structshape 이라는 함수를 제공하는 structshape 모듈을 작성했는데, 모든 종류의 자료 구조를 인자로 받아서 형태를 요약하는 문자열을 돌려줍니다. http://thinkpython.com/code/structshape.py에서 다운로드 할 수 있습니다.
여기에 단순한 리스트에 대한 결과가 있습니다:
>>> from structshape import structshape
>>> t = [1,2,3]
>>> print structshape(t)
list of 3 int
더 장식적인 프로그램은 “list of 3 ints,” 라고 쓸 수 있겠지만, 복수형을 다루지 않는 것이 더 쉽습니다. 여기에 리스트의 리스트가 있습니다:
>>> t2 = [[1,2], [3,4], [5,6]]
>>> print structshape(t2)
list of 3 list of 2 int
만약 리스트의 요소들이 같은 형이 아니라면, structshape 은 순서를 유지하면서 형 별로 묶습니다:
>>> t3 = [1, 2, 3, 4.0, '5', '6', [7], [8], 9]
>>> print structshape(t3)
list of (3 int, float, 2 str, 2 list of int, int)
여기에 튜플의 리스트가 있습니다:
>>> s = 'abc'
>>> lt = zip(t, s)
>>> print structshape(lt)
list of 3 tuple of (int, str)
그리고 여기에 정수를 문자열로 대응시키는 세 항목을 갖는 딕셔너리가 있습니다.
>>> d = dict(lt)
>>> print structshape(d)
dict of 3 int->str
여러분의 자료 구조를 쫓는데 어려움이 있다면, structshape 가 도움이 될 수 있습니다.
용어
- 튜플 tuple:
- 요소들의 수정 불가능한 시퀀스.
- 튜플 대입 tuple assignment:
- 우변에 시퀀스가, 좌변에 변수들의 튜플이 오는 대입. 우변이 환산된 후에 요소들이 좌변의 변수들에 대입됩니다.
- 수집 gather:
- 가변길이 인자 튜플을 만드는 연산.
- 산개 scatter:
- 시퀀스를 인자 목록으로 처리하는 연산.
- DSU:
- “decorate-sort-undecorate”의 약어로, 튜플 리스트를 만든 후 정렬하고 결과의 일부를 추출하는 작업을 수반하는 패턴.
- 자료 구조 data structure:
- 관련된 값들의 집합으로, 종종 리스트, 딕셔너리, 튜플 등으로 구성됩니다.
- (자료 구조의) 형태 shape:
- 자료 구조의 형, 크기, 조성(composition)의 요약.
연습
[연습 12.3.]
문자열을 받아들여서 빈도가 감소하는 순으로 글자들을 인쇄하는 함수 most_frequent를 작성하세요. 여러 종류의 언어에서 텍스트 샘플을 찾아서 언어별로 글자 빈도가 어떻게 달라지는지 보세요. 여러분의 결과를 http://en.wikipedia.org/wiki/Letter_frequencies 에 있는 표와 비교해 보세요. 답: http://thinkpython.com/code/most_frequent.py.
[연습 12.4.] [anagrams]
다시 보는 애너그램!
파일에서 단어 목록을 읽어서 ([wordlist] 절을 보세요) 애너그램을 이루는 모든 단어집합을 인쇄하는 프로그램을 작성하세요.
여기에 출력 예가 있습니다:
['deltas', 'desalt', 'lasted', 'salted', 'slated', 'staled'] ['retainers', 'ternaries'] ['generating', 'greatening'] ['resmelts', 'smelters', 'termless']
힌트: 글자 집합을 그 글자들로 구성되는 단어의 리스트로 대응하는 딕셔너리를 만들고 싶을 겁니다. 질문은 이겁니다, 어떻게 키로 사용될 수 있도록 글자의 집합을 표현할 수 있을까요?
가장 큰 애너그램 집합을 먼저 인쇄하고, 두 번째로 큰 집합을 그 다음에 인쇄하고, 그 나머지도 비슷한 방식으로 인쇄되도록 앞의 프로그램을 수정하세요.
스크래블(Scrabble)에서 “빙고(bingo)” 는 여러분 몫의 일곱 철자 모두와 보드의 한 글자를 써서 여덟 글자 단어를 만든 경우 입니다. 어떤 여덟 글자가 가장 확률이 높은 빙고를 구성할까요? 힌트: 7개 있습니다.
[연습 12.5.]
두 글자를 교환해서 한 단어를 다른 단어로 만들 수 있다면, 두 단어가 “자위 전환 쌍(metathesis pair)”을 이룬다고 합니다; 예를 들어, “converse” 와 “conserve” 같은 경우입니다. 앞의 문제에서 나온 딕셔너리에서 모든 자위 전환 쌍을 찾아내는 프로그램을 작성하세요. 힌트: 단어의 모든 쌍을 조사하지 말고, 모든 가능한 교환을 검사하지도 마세요. 답: http://thinkpython.com/code/metathesis.py. 출처: 이 연습은 http://puzzlers.org의 예에서 영감을 얻었습니다.
[연습 12.6.]
여기 또 하나의 Car Talk 퍼즐(http://www.cartalk.com/content/puzzlers)이 있습니다:
한 번에 한 글자씩 지워나가도, 계속 올바른 영어 단어로 남아있는, 가장 긴 영어 단어는 무엇일까요?
자, 글자는 양 끝과 중간 어디서든 지워질 수 있습니다만, 글자들을 재배열 할 수는 없습니다. 글자를 지울 때마다, 다른 영어 단어와 만나게 됩니다. 여러분이 그렇게 한다면, 결국 한 글자에 도달하게 되는데, 이 또한 사전에서 찾을 수 있는 영어 단어가 됩니다. 저는 가장 긴 단어가 무엇인지 알고 싶습니다, 몇 글자 단어인가요?
약간 평범한 예를 보여주겠습니다: Sprite. Ok? sprite 로 시작합니다, 한 글자를 지워야 하는데, 단어의 중간에서, r 을 때어내면 spite 가 남고, 끝의 e 를 지우면, spit 가 되며, s 를 지워서 pit 얻은 다음, it 을 거쳐 I 가 됩니다.
이런 식으로 줄여질 수 있는 모든 단어를 나열하는 프로그램을 작성하고, 가장 긴 것을 찾으세요.
이 연습은 다른 대부분의 것들 보다 약간 도전적이기 때문에, 여기 약간의 제안을 줍니다:
- 단어를 받아서 한 글자를 지워서 만들 수 있는 모든 단어들의 리스트를 계산하는 함수를 만들고 싶을 겁니다. 이 것들이 단어의 “자식들(children)” 입니다.
- 재귀적으로, 자식들 중 어느 하나라도 환원 가능할 때 단어를 환원 가능하다고 말합니다. 기저 사례로, 빈 문자열을 환원 가능하다고 취급할 수 있습니다.
- 제가 제공한 단어목록, words.txt,은 한 글자 단어를 포함하고 있지 않습니다. 그래서 여러분은 “I”, “a”, 빈 문자열을 추가하고 싶을 겁니다.
- 프로그램의 성능을 개선하기 위해, 환원 가능하다고 알려진 단어들을 메모화(memoize)하고 싶을 겁니다.