리스트
리스트는 시퀀스다
[sequence]
문자열처럼, 리스트(list)는 값의 시퀀스입니다. 문자열에서는, 값은 문자입니다; 리스트에서는 어떤 종류건 될 수 있습니다. 리스트에 들어있는 값들을 요소(element) 또는 때로 항목(item)이라고 부릅니다.
새로 리스트를 만드는 방법은 여러 가지 입니다; 가장 간단한 방법은 요소들을 대괄호 ([ and ])로 둘러싸는 것입니다:
[10, 20, 30, 40]
['crunchy frog', 'ram bladder', 'lark vomit']
첫 번째 예는 네 정수의 리스트입니다. 두 번째는 세 문자열의 리스트입니다. 리스트의 요소들은 서로 같은 종류일 필요가 없습니다. 다음 리스트는 문자열, 실수, 정수, (자!) 다른 리스트를 포함합니다:
['spam', 2.0, 5, [10, 20]]
다른 리스트 안의 리스트는 중첩(nested)됩니다.
요소가 없는 리스트를 빈 리스트라고 부릅니다; 빈 대괄호, [], 로 하나 만들 수 있습니다.
예상 하듯이, 리스트 값을 변수에 대입할 수 있습니다:
>>> cheeses = ['Cheddar', 'Edam', 'Gouda']
>>> numbers = [17, 123]
>>> empty = []
>>> print cheeses, numbers, empty
['Cheddar', 'Edam', 'Gouda'] [17, 123] []
리스트는 수정할 수 있다
[mutable]
리스트의 요소를 다루는 문법은 문자열의 문자를 다루는 경우와 동일합니다—대괄호 연산자. 대괄호 내부의 표현식은 지수를 지정합니다. 지수가 0에서 시작하는 것을 기억하세요:
>>> print cheeses[0]
Cheddar
문자열과 달리, 리스트는 수정 가능합니다. 대괄호 연산자가 대입의 좌변에 등장하면, 대입될 리스트의 요소를 지정합니다.
>>> numbers = [17, 123]
>>> numbers[1] = 5
>>> print numbers
[17, 5]
numbers 의 1번 요소, 123 이었던,는 이제 5입니다.
리스트를 지수와 요소간의 관계로 생각할 수 있습니다. 이 관계는 사상(mapping)이라고 불립니다; 각 지수는 하나의 원소에 “대응”합니다. 그림 [fig.liststate]은 cheeses, numbers, empty의 상태도를 보여줍니다.
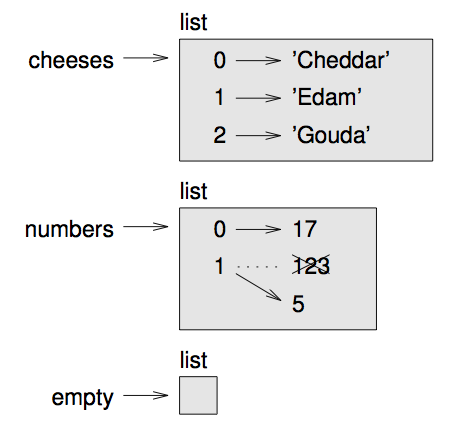
[fig.liststate]
리스트는 밖에 “list” 라는 단어가 붙어있고, 안에 리스트의 요소들이 들어있는 상자로 나타냅니다. cheeses는 지수 0, 1, 2에 대응하는 세 개의 요소를 갖는 리스트를 가리킵니다. numbers는 두 개의 요소를 갖고 있습니다; 다이어그램은 두 번째 요소가 123에서 5로 다시 대입되었음을 보여주고 있습니다. empty는 요소가 없는 리스트를 가리킵니다.
리스트 지수는 문자열 지수와 같은 식으로 기능합니다:
- 모든 정수 표현식은 지수로 사용될 수 있습니다.
- 존재하지 않는 요소를 읽거나 쓰려고 하면 IndexError를 얻게 됩니다.
- 지수가 음수 값이면 리스트의 끝에서부터 거꾸로 셉니다..
in 연산자도 리스트에 사용할 수 있습니다.
>>> cheeses = ['Cheddar', 'Edam', 'Gouda']
>>> 'Edam' in cheeses
True
>>> 'Brie' in cheeses
False
리스트 탐색
리스트의 요소들을 탐색하는 가장 일반적인 방법은 for 순환입니다. 문법은 문자열과 같습니다:
for cheese in cheeses:
print cheese
리스트의 요소를 읽기만 할 거라면 잘 동작합니다. 하지만 요소를 쓰거나 갱신하려면 지수가 필요합니다. 그렇게 하는 일반적인 방법은 함수 range 와 len을 함께 쓰는 것입니다:
for i in range(len(numbers)):
numbers[i] = numbers[i] * 2
이 순환은 리스트를 탐색하고 각 요소를 갱신합니다. len은 리스트에 있는 요소의 개수를 돌려줍니다. range는, \(n\) 이 리스트의 길이일 때, 0 에서 \(n-1\) 까지의 지수로 구성된 리스트를 돌려줍니다. 매 순환마다 i는 다음 요소의 지수가 됩니다. 바디의 대입문은 요소의 예전 값을 읽고, 새 값을 대입하는데 i를 사용합니다.
빈 리스트에 대한 for 순환은 바디를 전혀 실행하지 않습니다:
for x in []:
print '절대로 일어나지 않아요.'
설사 리스트가 다른 리스트를 포함한다고 해도, 중첩된 리스트는 여전히 하나의 요소로 취급됩니다. 이 리스트의 길이는 4입니다:
['spam', 1, ['Brie', 'Roquefort', 'Pol le Veq'], [1, 2, 3]]
리스트 연산
- 연산자는 리스트를 접합합니다:
>>> a = [1, 2, 3]
>>> b = [4, 5, 6]
>>> c = a + b
>>> print c
[1, 2, 3, 4, 5, 6]
마찬가지로, 연산자는 주어진 횟수만큼 리스트를 반복합니다:
>>> [0] * 4
[0, 0, 0, 0]
>>> [1, 2, 3] * 3
[1, 2, 3, 1, 2, 3, 1, 2, 3]
첫째 예는 를 네 번 반복합니다. 두 번째 예는 리스트 를 세 번 반복합니다.
리스트 슬라이스
슬라이스 연산자 역시 리스트에 사용됩니다:
>>> t = ['a', 'b', 'c', 'd', 'e', 'f']
>>> t[1:3]
['b', 'c']
>>> t[:4]
['a', 'b', 'c', 'd']
>>> t[3:]
['d', 'e', 'f']
첫 번째 지수를 생략하면, 슬라이스는 처음부터 시작합니다. 두 번째를 생략하면, 슬라이스는 끝까지 갑니다. 그래서 둘 다 생략하면, 슬라이스는 리스트 전체의 복사본이 됩니다.
>>> t[:]
['a', 'b', 'c', 'd', 'e', 'f']
리스트는 수정 가능하기 때문에, 리스트를 접고, 늘리고, 자르는 연산을 수행하기 전에 사본을 만드는 것은 종종 쓸모 있습니다.
대입의 좌변에 오는 슬라이스 연산자는 여러 개의 요소를 갱신할 수 있습니다:
>>> t = ['a', 'b', 'c', 'd', 'e', 'f']
>>> t[1:3] = ['x', 'y']
>>> print t
['a', 'x', 'y', 'd', 'e', 'f']
리스트 메쏘드
파이썬은 리스트에 작용하는 메쏘드들을 제공합니다. 예를 들어, append는 새 요소를 리스트의 끝에 추가합니다:
>>> t = ['a', 'b', 'c']
>>> t.append('d')
>>> print t
['a', 'b', 'c', 'd']
extend는 인자로 리스트를 받아서 모든 요소들을 뒤에 추가합니다:
>>> t1 = ['a', 'b', 'c']
>>> t2 = ['d', 'e']
>>> t1.extend(t2)
>>> print t1
['a', 'b', 'c', 'd', 'e']
이 예는 t2를 수정되지 않은 상태로 둡니다.
sort는 리스트를 올림차순으로 정렬합니다:
>>> t = ['d', 'c', 'e', 'b', 'a']
>>> t.sort()
>>> print t
['a', 'b', 'c', 'd', 'e']
리스트 메쏘드는 모두 결과가 없습니다; 리스트를 수정한 후 None을 돌려줍니다. 만약 여러분이 실수로 t = t.sort() 라고 쓴다면, 결과에 실망하게 될 것입니다.
변환, 여과, 환원
리스트에 있는 모든 숫자들을 더하려면, 이런 식으로 순환을 사용할 수 있습니다:
def add_all(t):
total = 0
for x in t:
total += x
return total
total 은 0으로 초기화됩니다. 매 순환마다, x는 리스트의 한 요소를 취합니다. += 연산자는 변수를 갱신하는 간단한 방법을 제공합니다. 이 증강 대입문(augmented assignment statement):
total += x
은 이 것과 동일합니다:
total = total + x
순환이 실행됨에 따라, total은 요소들의 합을 쌓아나갑니다; 이런 식으로 사용되는 변수를 누산기(accumulator)라고 부릅니다.
리스트의 요소들을 더하는 것은 자주 쓰는 연산이기 때문에, 파이썬은 내장함수 sum을 제공합니다:
>>> t = [1, 2, 3]
>>> sum(t)
6
이런 식으로 요소들의 시퀀스를 하나의 값으로 결합하는 연산을 때로 환원(reduce)이라고 부릅니다.
[연습 10.1.]
중첩된 정수 리스트를 받아서 중첩된 리스트 모두의 요소들을 더하는 함수 nested_sum을 작성하세요.
때로 한 리스트를 만들면서 다른 리스트를 탐색할 필요가 있습니다. 예를 들어, 다음 함수는 문자열의 리스트를 받아서 대문자로 시작시킨 문자열들로 구성된 리스트를 돌려줍니다:
def capitalize_all(t):
res = []
for s in t:
res.append(s.capitalize())
return res
res는 빈 리스트로 초기화됩니다; 매 순환마다, 다음 요소를 덧붙입니다. 그래서 res는 다른 종류의 누산기 입니다.
capitalize_all과 같은 연산은 때로 변환(map)이라고 불리는데, 함수(이 경우는 capitalize 메쏘드)로 시퀀스의 각 요소를 변환시키기 때문입니다.
[연습 10.2.]
중첩된 문자열의 리스트를 받아서, 대문자로 시작하도록 바뀐 모든 문자열들로 구성된 리스트를 돌려주는 함수 capitalize_nested를 작성하는데 capitalize_all를 사용하세요.
또 하나의 빈번한 연산으로 리스트의 요소들중 일부를 선택해서 부분리스트를 돌려주는 것이 있습니다. 예를 들어, 다음 함수는 문자열의 리스트들 받아서 대문자 문자열들만을 골라낸 리스트를 돌려줍니다:
def only_upper(t):
res = []
for s in t:
if s.isupper():
res.append(s)
return res
isupper 는 문자열이 대문자만으로 구성되어 있을 때 True를 돌려주는 문자열 메쏘드입니다.
only_upper와 같은 종류의 연산을 여과(filter)라고 부르는데, 요소들의 일부를 선택하고 나머지들을 걸러내기 때문입니다.
자주 만나는 리스트 연산들의 대부분은 변환, 여과, 환원의 조합으로 표현될 수 있습니다. 이 연산들이 아주 자주 쓰이기 때문에, 파이썬은 이를 지원하는 언어 기능을 제공하는데, 내장함수 map과 “리스트 함축(list comprehension)” 이라고 불리는 연산자를 포함합니다.
[연습 10.3.] [cumulative]
숫자의 리스트를 받아들여서 누적 합(cumulative sum)을 돌려주는 함수를 작성하세요; 즉, 결과는 새 리스트인데 \(i\) 번 요소는 원래 리스트의 처음 \(i+1\) 개 요소의 합입니다. 예를 들어, 의 누적 합은 입니다.
요소 삭제
리스트에서 요소를 지우는 방법은 여러 가지가 있습니다. 원하는 요소의 지수를 알고 있다면, pop을 쓸 수 있습니다:
>>> t = ['a', 'b', 'c']
>>> x = t.pop(1)
>>> print t
['a', 'c']
>>> print x
b
pop은 리스트를 수정하고 삭제된 요소를 돌려줍니다. 지수를 제공하지 않으면, 마지막 요소를 삭제하고 돌려줍니다.
지운 값이 필요 없다면, del 연산자를 사용할 수 있습니다:
>>> t = ['a', 'b', 'c']
>>> del t[1]
>>> print t
['a', 'c']
지우려는 요소를 안다면(하지만 지수는 모른다면), remove를 사용할 수 있습니다:
>>> t = ['a', 'b', 'c']
>>> t.remove('b')
>>> print t
['a', 'c']
remove의 반환 값은 None입니다.
한 개 이상의 요소를 지울 때는, del 과 슬라이스 지수를 사용할 수 있습니다:
>>> t = ['a', 'b', 'c', 'd', 'e', 'f']
>>> del t[1:5]
>>> print t
['a', 'f']
보통, 슬라이스는 두 번째 지수까지의 모든 (그러나 두 번째 지수는 제외하고) 요소를 선택합니다.
[연습 10.4.]
리스트를 받아서 처음과 끝을 제외한 모든 요소를 돌려주는 함수 middle 를 작성하세요. 그래서, middle([1,2,3,4]) 는 [2,3] 를 돌려줘야 합니다.
[연습 10.5.]
리스트를 받아서 처음과 마지막 요소를 지우는 방식으로 수정한 후 None을 돌려주는 함수 chop을 작성하세요.
리스트와 문자열
문자열은 문자의 시퀀스고, 리스트는 값의 시퀀스입니다만, 문자의 리스트가 문자열과 같은 것은 아닙니다. 문자열을 문자의 리스트로 바꾸려면, list를 사용할 수 있습니다:
>>> s = 'spam'
>>> t = list(s)
>>> print t
['s', 'p', 'a', 'm']
list는 내장함수의 이름이기 때문에, 변수 명으로 사용하는 것은 피해야 합니다. 저는 l도 사용하지 않는데, 1과 너무 비슷해 보이기 때문입니다. 이 것이 제가 t를 사용한 이유입니다.
list 함수는 문자열을 각각의 글자로 분해합니다. 문자열을 단어로 분해하고 싶다면, split 메쏘드를 사용할 수 있습니다:
>>> s = 'pining for the fjords'
>>> t = s.split()
>>> print t
['pining', 'for', 'the', 'fjords']
생략 가능한 구획문자(delimiter)라고 불리는 인자는, 단어의 경계로 사용할 문자를 지정합니다. 다음 예는 하이픈(hyphen)을 구획문자로 사용합니다:
>>> s = 'spam-spam-spam'
>>> delimiter = '-'
>>> s.split(delimiter)
['spam', 'spam', 'spam']
join은 split의 역입니다. 문자열의 리스트를 받아서 요소들을 접합합니다. join은 문자열 메쏘드이기 때문에, 구획문자에 대해 호출하고 리스트를 매개변수로 전달해야 합니다:
>>> t = ['pining', 'for', 'the', 'fjords']
>>> delimiter = ' '
>>> delimiter.join(t)
'pining for the fjords'
이 경우에 구획문자는 공백 문자이고, join은 단어 사이에 공백을 넣습니다. 공백없이 문자열을 접합하려면, 빈 문자열, '', 을 구획 문자로 사용할 수 있습니다.
객체와 값
이 대입 문들을 실행하면:
a = 'banana'
b = 'banana'
a 와 b 가 문자열을 가리킨다는 것을 압니다만, 그들이 같은 문자열을 가리키는지 여부는 모릅니다. 두 가지 가능한 상태가 있는데, 그림 [fig.list1]에 있습니다.

[fig.list1]
한 가지 경우는, a 와 b 가 같은 값을 갖고 있는 두 개의 다른 객체를 가리킵니다. 두 번째 경우는, 둘 다 같은 객체를 가리킵니다.
두 변수가 같은 객체를 가리키는지 확인하려면, is 연산자를 사용할 수 있습니다.
>>> a = 'banana'
>>> b = 'banana'
>>> a is b
True
이 예에서, 파이썬은 단지 하나의 문자열 객체만을 만들고, a 와 b 모두 그 것을 가리킵니다.
그러나 두 개의 리스트를 만들면, 두 개의 객체를 얻습니다:
>>> a = [1, 2, 3]
>>> b = [1, 2, 3]
>>> a is b
False
그래서 상태도는 그림 [fig.list2] 처럼 보입니다.
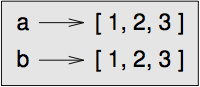
[fig.list2]
이 경우에 두 개의 리스트는 동등(equivalent)하다고 하는데, 같은 요소들을 갖고 있기 때문입니다. 그러나 동일(identical)하지는 않은데, 같은 객체가 아니기 때문입니다. 두 객체가 동일하다면, 두 객체는 저절로 동등합니다. 하지만 동등하다고 해서 필연적으로 동일한 것은 아닙니다.
지금까지, 우리는 “객체(object)” 와 “값(value)” 을 구별하지 않고 사용해왔습니다만, 객체가 값을 갖는다고 말하는 것이 좀 더 정확합니다. 를 실행하면 정수의 시퀀스를 값으로 갖는 객체를 얻게 됩니다. 만약 다른 리스트가 값은 요소들을 갖는다면, 같은 값을 갖는다고 말할 수는 있지만, 같은 객체는 아닙니다.
에일리어스
a가 객체를 가리키고, b = a 로 대입했다면, 두 변수는 같은 객체를 가리키게 됩니다:
>>> a = [1, 2, 3]
>>> b = a
>>> b is a
True
상태도는 그림 [fig.list3] 처럼 보입니다.
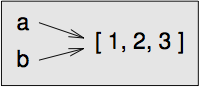
[fig.list3]
변수를 객체에 관련 짓는 것을 참조(reference)라고 부릅니다. 이 예에서, 같은 객체에 두 개의 참조가 있습니다.
하나 이상의 참조를 갖는 객체는 하나 이상의 이름이 있는 것이기 때문에, 객체가 에일리어스 되었다(aliased)고 합니다.
만약 에일리어스된 객체가 수정 가능하다면, 하나의 에일리어스를 통해 가해진 변경은 다른 것에 영향을 줍니다:
>>> b[0] = 17
>>> print a
[17, 2, 3]
이런 행동이 유용할 수도 있지만, 오류를 일으키기에 좋습니다. 일반적으로, 수정 가능한 객체를 다룰 때는 에일리어스를 피하는 편이 안전합니다.
문자열과 같이 수정 불가능한 객체의 경우는, 에일리어스가 별로 문제되지 않습니다. 이 예에서:
a = 'banana'
b = 'banana'
a 와 b가 같은 객체를 가리키거나 말거나 별다른 차이를 주지 못합니다.
리스트 인자
[list.arguments]
리스트를 함수에 전달할 때, 함수는 리스트로의 참조를 받습니다. 만약 함수가 리스트 매개변수를 수정한다면, 호출 자는 변경을 보게 됩니다. 예를 들어, delete_head 는 리스트에서 첫 번째 요소를 지웁니다:
def delete_head(t):
del t[0]
여기에 사용 예가 있습니다:
>>> letters = ['a', 'b', 'c']
>>> delete_head(letters)
>>> print letters
['b', 'c']
매개변수 t 와 변수 letters 는 같은 객체에 대한 에일리어스입니다. 스택 다이어그램은 그림 [fig.stack5] 처럼 보입니다.
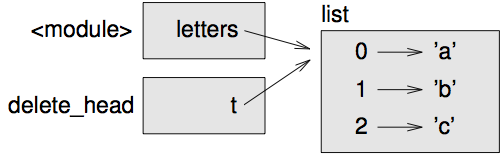
[fig.stack5]
리스트가 두 개의 프레임에 공유되기 때문에, 둘 사이에 그렸습니다.
리스트를 수정하는 연산과 새 리스트를 만드는 연산을 구별하는 것은 중요합니다. 예를 들어, append 메쏘드는 리스트를 수정하지만, + 연산자는 새 리스트를 만듭니다:
>>> t1 = [1, 2]
>>> t2 = t1.append(3)
>>> print t1
[1, 2, 3]
>>> print t2
None
>>> t3 = t1 + [4]
>>> print t3
[1, 2, 3, 4]
리스트를 수정하기로 한 함수를 작성할 때 이 차이는 중요합니다. 예를 들어, 이 함수는 리스트의 머리를 지우지 않습니다:
def bad_delete_head(t):
t = t[1:] # WRONG!
슬라이스 연산자는 새 리스트를 만들고, 대입은 t가 그 것을 가리키도록 만듭니다. 하지만, 그 어느 것도 인자로 전달된 리스트에 영향을 주지는 못합니다.
대안은 새 리스트를 만들어서 돌려주는 함수를 작성하는 것입니다. 예를 들어, tail 은 처음을 제외한 리스트의 모든 요소를 돌려줍니다:
def tail(t):
return t[1:]
이 함수는 원래 리스트를 수정되지 않은 상태로 남겨둡니다. 여기 사용 예가 있습니다:
>>> letters = ['a', 'b', 'c']
>>> rest = tail(letters)
>>> print rest
['b', 'c']
디버깅
리스트 (와 다른 수정 가능한 객체들)의 부주의한 사용은 긴 시간의 디버깅으로 이어질 수 있습니다. 여기 자주 만나는 함정들과 회피 법이 있습니다:
대부분의 리스트 메쏘드가 인자를 수정하고 None을 돌려준다는 것을 잊지 마세요. 이 것은 새 문자열을 돌려주고 원본은 그대로 두는 문자열 메쏘드들과는 반대입니다.
여러분이 문라열 코드를 이런 식으로 써 왔다면:
word = word.strip()
리스트 코드도 이렇게 쓰고 싶은 게 당연합니다:
t = t.sort() # WRONG!
sort는 None을 도려주기 때문에, t 로 수행할 다음 연산에서 실패하게 됩니다.
리스트 메쏘드와 연산자를 사용하기 전에, 설명서를 주의 깊게 읽고 대화형 모드에서 실험하도록 해야 합니다. 리스트가 다른 시퀀스(문자열 같은)들과 공유하는 메쏘드와 연산자들은 http://docs.python.org/2/library/stdtypes.html#typesseq에 문서화되어 있습니다. 수정 가능한 시퀀스들에만 적용되는 메쏘드와 연산자들은 http://docs.python.org/2/library/stdtypes.html#typesseq-mutable에 문서화되어 있습니다.
관용구를 선택한 후에 계속 사용하세요.
리스트와 관련된 문제의 일부는 같은 일을 수행하는 너무 많은 방법이 있다는 것입니다. 예를 들어, 리스트에서 요소를 지우기 위해, pop, remove, del 또는 슬라이스 대입을 사용할 수 있습니다.
요소를 추가하기 위해, append 메쏘드나 + 연산자를 사용할 수 있습니다. t 가 리스트고, x 가 리스트 요소라고 가정할 때, 이 것들은 모두 옳습니다:
t.append(x) t = t + [x]
그리고 이 것들은 잘못되었습니다:
t.append([x]) # WRONG! t = t.append(x) # WRONG! t + [x] # WRONG! t = t + x # WRONG!
이 예들을 대화형 모드에서 실험해서 이 것들이 무엇을 하는지 확실히 이해하도록 하세요. 마지막 것만 실행시간 오류를 일으킴에 주목하세요; 다른 세가지는 올바르게 실행되지만 잘못된 일을 합니다.
에일리어스를 피하기 위해 사본을 만드세요.
sort 처럼 인자를 수정하는 메쏘드를 사용하고 싶지만, 원본 리스트를 유지해야 할 필요가 있다면, 사본을 만들 수 있습니다.
orig = t[:] t.sort()
이 예에서 내장함수 sorted를 사용할 수도 있는데, 원본은 건드리지 않고 새로 만든 정렬된 리스트를 돌려줍니다. 그러나 그 경우에 sorted를 변수 명으로 사용하지 않아야 합니다!
용어
- 리스트 list:
- 값의 시퀀스.
- 요소 element:
- 리스트(또는 다른 시퀀스)에 있는 한 개의 값으로 항목(item)이라고도 불린다.
- 지수 index:
- 리스트의 요소를 가리키는 정수 값.
- 중첩 리스트 nested list:
- 다른 리스트의 요소인 리스트.
- 리스트 탐색 list traversal:
- 리스트의 각 요소들에 순차적으로 접근하는 것.
- 사상 mapping:
- 한 집합의 각 요소들을 다른 집합의 요소들에 대응시키는 관계. 예를 들어, 리스트는 지수에서 요소로의 사상이다.
- 누산기 accumulator:
- 순환에서 결과를 더하거나 누적시키는데 사용되는 변수.
- 증강 대입 augmented assignment:
- += 과 같은 연산자를 사용하여 변수의 값을 갱신하는 문장.
- 환원 reduce:
- 시퀀스를 탐색하여 요소들을 하나의 값으로 누적시키는 처리 방식.
- 변환 map:
- 시퀀스를 탐색하여 각 요소에 연산을 수행하는 처리 방식.
- 여과 filter:
- 시퀀스를 탐색하여 어떤 기준을 만족하는 요소들을 골라내는 처리 방식.
- 객체 object:
- 변수가 가리킬 수 있는 어떤 것. 객체는 형(type)과 값을 갖는다.
- 동등 equivalent:
- 같은 값을 갖는 것.
- 동일 identical:
- 각은 객체가 되는 것 (자동적으로 동등해진다).
- 참조 reference:
- 변수와 그 값의 결합.
- 에일리어싱 aliasing:
- 둘 또는 그 이상의 변수가 같은 객체를 가리키는 상황.
- 구획문자 delimiter:
- 문자열이 분리될 위치를 가리키는데 사용되는 문자나 문자열.
연습
[연습 10.6.] 리스트를 매개변수로 받아서, 리스트가 오름차순으로 정렬되어 있다면 True를, 그렇지 않다면 False를 돌려주는 함수 is_sorted를 작성하세요. 리스트의 요소가 <, >, 등의 비교 연산자들로 비교될 수 있다고 (사전조건으로) 가정할 수 있습니다.
예를 들어, is_sorted([1,2,2]) 는 True를 돌려주고, is_sorted(['b','a'])는 False를 돌려줘야 합니다.
[연습 10.7.] [anagram]
한 단어의 철자를 재배치해서 다른 단어를 만들어 낼 수 있다면 두 단어를 애너그램이라고 합니다. 두 개의 문자열을 받아서 애너그램이면 True를 돌려주는 함수 is_anagram 을 작성하세요.
[연습 10.8.] [duplicate]
(소위) 생일 역설:
- 리스트를 받아서 두 번 이상 등장하는 요소가 있으면 True를 돌려주는 함수 has_duplicates를 작성하세요. 원본 리스트는 수정하지 않아야 합니다.
- 여러분의 반에 23명의 학생이 있다면, 그 중 두 명의 생일이 같을 확률은 얼마일까요? 임의의 생일 23개를 만들어 같은 값이 있는지 조사하는 방식으로 이 확률을 추정할 수 있습니다. 힌트: random 모듈에 있는 randint 함수로 임의의 생일을 만들 수 있습니다.
http://en.wikipedia.org/wiki/Birthday_paradox에서 이 문제에 대한 글을 읽을 수 있고, 제 답을 http://thinkpython.com/code/birthday.py에서 다운로드 할 수 있습니다.
[연습 10.9.]
리스트를 받아서 겹치는 원소들을 제거한 새 리스트를 돌려주는 함수 remove_duplicates 를 작성하세요. 힌트: 순서가 같을 필요는 없습니다.
[연습 10.10.]
파일 words.txt를 읽어서 각 단어를 요소로 하는 리스트를 만드는 함수를 작성하세요. 이 함수를 두 가지 버전으로 작성하는데, 하나는 append 메쏘드를 사용하고, 다른 하나는 관용구 t = t + [x]를 사용합니다. 어느 버전이 실행하는데 더 오래 걸릴까요? 왜 그럴까요?
힌트: 소요시간을 측정하는데 time 모듈을 사용하세요. 답: http://thinkpython.com/code/wordlist.py.
[연습 10.11.] [wordlist1] [bisection]
단어가 단어 리스트에 있는지 검사하기 위해, in 연산자를 사용할 수 있습니다만, 단어를 순서대로 검사하기 때문에 느릴 것입니다.
단어들은 알파벳 순이기 때문에, 이분 검색(이진 검색으로도 알려져 있습니다)으로 속도를 올릴 수 있는데, 여러분이 사전에서 단어를 찾을 때 하는 것과 유사합니다. 여러분은 가운데에서 시작해서 찾는 단어가 리스트의 가운데에 있는 단어의 앞에 오는지 여부를 확인합니다. 그렇다면, 같은 방법으로 리스트의 전반부를 검색합니다. 그렇지 않으면 후반부를 검색합니다.
어느 경우든, 남은 검색 공간을 반으로 줄이게 됩니다. 만약 단어 리스트가 113,809 단어를 갖고 있다면, 단어를 찾거나 없음을 확인하는데 17 단계가 필요합니다.
정렬된 리스트와 목표 값을 받아서 있다면 리스트에서의 지수를, 없다면 None 을 돌려주는 함수 bisect를 작성하세요.
또는 bisect 모듈의 설명서를 읽고 그 걸 사용해도 됩니다! 답: http://thinkpython.com/code/inlist.py.
[연습 10.12.]
만약 서로 상대방을 뒤집어서 만들어지는 경우 두 단어를 “reverse pair” 라고 합니다. 단어 리스트에서 모든 reverse pair 를 찾는 프로그램을 작성하세요. 답: http://thinkpython.com/code/reverse_pair.py.
[연습 10.13.]
각각의 단어에서 글자를 번갈아 취해서 만들어지는 조합이 새 단어를 이룰 경우 두 단어를 “얽혔다(interlock)” 고 합니다. 예를 들어, “shoe” 와 “cold” 는 얽혀서 “schooled”를 만듭니다. 답: http://thinkpython.com/code/interlock.py. 크레디트: 이 연습은 http://puzzlers.org 에 있는 예에서 영감을 받았습니다.
- 서로 얽히는 모든 단어 쌍을 찾는 프로그램을 작성하세요. 힌트: 모든 쌍을 나열하지 마세요!
- 삼중으로 얽힌 단어들을 찾을 수 있습니까? 즉, 첫 번째, 두 번째, 세 번째 글자에서 시작해서 세 칸씩 건너뛰며 모은 글자들이 각각 단어를 이룹니다.